

My project
AMD Instinct™ MI300 Series
Accelerators
Leadership Generative AI Accelerators and Data Center APUs

Supercharging AI and HPC
AMD Instinct™ MI300 Series accelerators are uniquely well-suited to power even the most demanding AI and HPC workloads, offering exceptional compute performance, large memory density, high bandwidth memory, and support for specialized data formats.
Under the Hood
AMD Instinct MI300 Series accelerators are built on AMD CDNA™ 3 architecture, which offers Matrix Core Technologies and support for a broad range of precision capabilities—from the highly efficient INT8 and FP8 (including sparsity support for AI), to the most demanding FP64 for HPC.
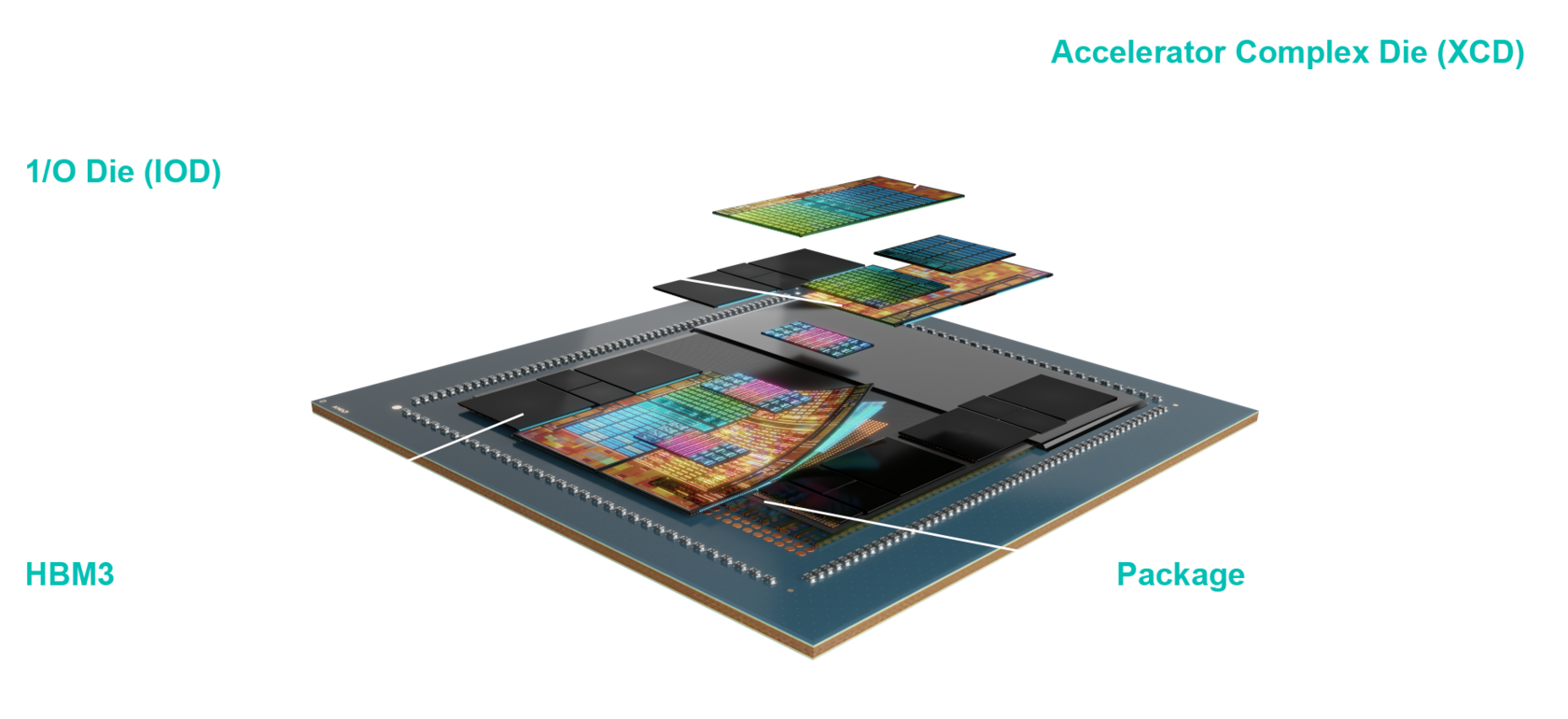
Meet the Series
Explore AMD Instinct MI300X accelerators, the AMD Instinct MI300X Platform, and AMD Instinct MI300A APUs.
AMD Instinct MI300X Accelerators
AMD Instinct MI300X Series accelerators are designed to deliver leadership performance for Generative AI workloads and HPC applications.



- 304 CUs304 GPU Compute Units
- 192 GB192 GB HBM3 Memory
- 5.3 TB/s5.3 TB/s Peak Theoretical Memory Bandwidth
Offers approximately 6.8X the Al training workload performance using FP8 vs. MI250 accelerators using FP161
Runs Hugging Face OPT transformer Large Language Model (LLM) on 66B parameter on 1 GPU2
AMD Instinct MI300X Platform
The AMD Instinct MI300X Platform integrates 8 fully connected MI300X GPU OAM modules onto an industry-standard OCP design via 4th-Gen AMD Infinity Fabric™ links, delivering up to 1.5TB HBM3 capacity for low-latency AI processing. This ready-to-deploy platform can accelerate time-to-market and reduce development costs when adding MI300X accelerators into existing AI rack and server infrastructure.

- 8 MI300X8 MI300X GPU OAM modules
- 1.5 TB1.5 TB Total HBM3 Memory
- 42.4 TB/s42.4 TB/s Peak Theoretical Aggregate Memory Bandwidth
Expected to deliver 20.9 PFLOPs FP16 and BF16 peak theoretical floating-point performance with sparsity3
AMD Instinct MI300A APUs
AMD Instinct MI300A accelerated processing units (APUs) combine the power of AMD Instinct accelerators and AMD EPYC™ processors with shared memory to enable enhanced efficiency, flexibility, and programmability. They are designed to accelerate the convergence of AI and HPC, helping advance research and propel new discoveries.

- 228 CUs228 GPU Compute Units
- 2424 “Zen 4” x86 CPU Cores
- 128 GB128 GB Unified HBM3 Memory
- 5.3 TB/s5.3 TB/s Peak Theoretical Memory Bandwidth
Offers approximately 2.6X the HPC workload performance per watt using FP32 compared to AMD MI250X accelerators4
Request consultation
Contact ASBIS Experts to get more information about AMD EPYC processors.
- Measurements conducted by AMD Performance Labs as of November 11th, 2023 on the AMD Instinct™ MI300X (750W) GPU designed with AMD CDNA™ 3 5nm | 6nm FinFET process technology at 2,100 MHz peak boost engine clock resulted in 653.7 TFLOPS peak theoretical TensorFloat-32 (TF32), 1307.4 TFLOPS peak theoretical half precision (FP16), 1307.4 TFLOPS peak theoretical Bfloat16 format precision (BF16), 2614.9 TFLOPS peak theoretical 8-bit precision (FP8), 2614.9 TOPs INT8 floating-point performance. The MI300X is expected to be able to take advantage of fine-grained structure sparsity providing an estimated 2x improvement in math efficiency resulting 1,307.4 TFLOPS peak theoretical TensorFloat-32 (TF32), 2,614.9 TFLOPS peak theoretical half precision (FP16), 2,614.9 TFLOPS peak theoretical Bfloat16 format precision (BF16), 5,229.8 TFLOPS peak theoretical 8-bit precision (FP8), 5,229.8 TOPs INT8 floating-point performance with sparsity. The results calculated for the AMD Instinct™ MI250X (560W) 128GB HBM2e OAM accelerator designed with AMD CDNA™ 2 5nm FinFET process technology at 1,700 MHz peak boost engine clock resulted in TF32* (N/A), 383.0 TFLOPS peak theoretical half precision (FP16), 383.0 TFLOPS peak theoretical Bfloat16 format precision (BF16), FP8* (N/A), 383.0 TOPs INT8 floating-point performance. *AMD Instinct MI200 Series GPUs don’t support TF32, FP8 or sparsity. MI300-16
- Measurements by internal AMD Performance Labs as of June 2, 2023 on current specifications and/or internal engineering calculations. Large Language Model (LLM) run or calculated with FP16 precision to determine the minimum number of GPUs needed to run the Falcon-7B (7B, 40B parameters), LLaMA (13B, 33B parameters), OPT (66B parameters), GPT-3 (175B parameters), BLOOM (176B parameter), and PaLM (340B, 540B parameters) models. Calculated estimates based on GPU-only memory size versus memory required by the model at defined parameters plus 10% overhead. Calculations rely on published and sometimes preliminary model memory sizes. GPT-3, BLOOM, and PaML results estimated on MI300X due to system/part availability. Tested result configurations: AMD Lab system consisting of 1x EPYC 9654 (96-core) CPU with 1x AMD Instinct™ MI300X (192GB HBM3, OAM Module) 750W accelerator.
- Measurements conducted by AMD Performance Labs as of November 18th, 2023 on the AMD Instinct™ MI300X (192 GB HBM3) 750W GPU designed with AMD CDNA™ 3 5nm | 6nm FinFET process technology at 2,100 MHz peak boost engine clock resulted in 1307.4 TFLOPS peak theoretical half precision (FP16), 1307.4 TFLOPS peak theoretical Bfloat16 format precision (BF16). The MI300X is expected to be able to take advantage of fine-grained structure sparsity providing an estimated 2x improvement in math efficiency resulting 2,614.9 TFLOPS peak theoretical half precision (FP16), 2,614.9 TFLOPS peak theoretical Bfloat16 format precision (BF16 floating-point performance with sparsity. Published results on Nvidia H100 SXM (80GB HBM3) 700W GPU resulted in 1,978.9 TFLOPS peak theoretical half precision (FP16) with sparsity, 1,978.9 TFLOPS peak theoretical Bfloat16 format precision (BF16) with sparsity floating-point performance. Nvidia H100 source: https://resources.nvidia.com/en-us-tensor-core/ AMD Instinct™ MI300X AMD CDNA 3 technology-based accelerators include up to eight AMD Infinity Fabric links providing up to 1,024 GB/s peak aggregate theoretical GPU peer-to-peer (P2P) transport rate bandwidth performance per GPU OAM module. MI300-25.
- Measurements conducted by AMD Performance Labs as of November 18th, 2023 on the AMD Instinct™ MI300X (192 GB HBM3) 750W GPU designed with AMD CDNA™ 3 5nm | 6nm FinFET process technology at 2,100 MHz peak boost engine clock resulted in 1307.4 TFLOPS peak theoretical half precision (FP16), 1307.4 TFLOPS peak theoretical Bfloat16 format precision (BF16). The MI300X is expected to be able to take advantage of fine-grained structure sparsity providing an estimated 2x improvement in math efficiency resulting 2,614.9 TFLOPS peak theoretical half precision (FP16), 2,614.9 TFLOPS peak theoretical Bfloat16 format precision (BF16 floating-point performance with sparsity. Published results on Nvidia H100 SXM (80GB HBM3) 700W GPU resulted in 1,978.9 TFLOPS peak theoretical half precision (FP16) with sparsity, 1,978.9 TFLOPS peak theoretical Bfloat16 format precision (BF16) with sparsity floating-point performance. Nvidia H100 source: https://resources.nvidia.com/en-us-tensor-core/ AMD Instinct™ MI300X AMD CDNA 3 technology-based accelerators include up to eight AMD Infinity Fabric links providing up to 1,024 GB/s peak aggregate theoretical GPU peer-to-peer (P2P) transport rate bandwidth performance per GPU OAM module. MI300-25

©2024 Advanced Micro Devices, Inc. All rights reserved.
AMD, the AMD logo, EPYC, and combinations thereof are trademarks of Advanced Micro Devices, Inc.
AMD, the AMD logo, EPYC, and combinations thereof are trademarks of Advanced Micro Devices, Inc.